Exporting access logs to a CSV file
Access logs give you a picture of who is accessing what in your account. The access logs track the last 90 days of access activity by admins and agents but not end users. The Access Logs API allows you to export the access logs.
Access logs drive accountability by identifying data security risks, refining security and privacy policies, and supporting data privacy compliance. For example, you can use the data provided by the access logs to establish proper permissions for your agents with custom agent roles. See Creating custom roles and assigning agents in Zendesk help.
Access logs are only available with the Zendesk Advanced Data Privacy and Protection add-on.
This article provides a demo script that answers the following questions:
- What tickets are agents accessing?
- What user profiles are agents accessing?
The script uses the Access Logs API to export the agents' access logs to a CSV (comma-separated values) file for further analysis.
The script asks the user for a resource (tickets or users) and the number of days back to look for logs:
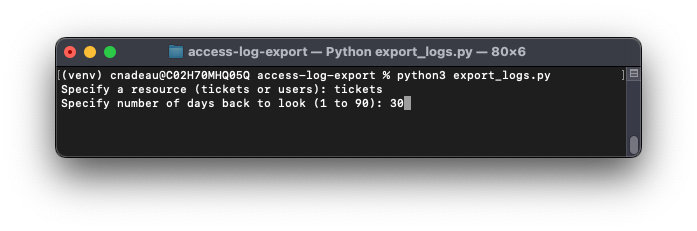
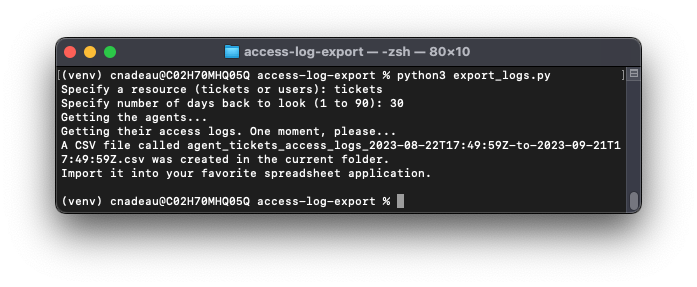
The script gets the agents in the account, retrieves their access logs, filters them for the specified resource, and writes a CSV file:
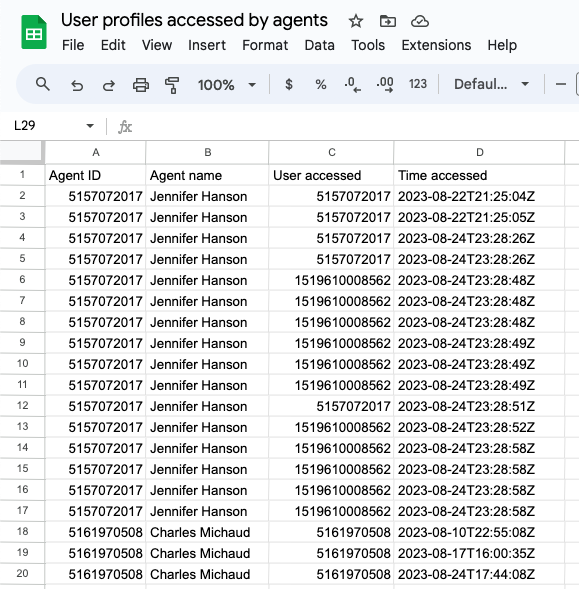
Then you can import the CSV file in any spreadsheet application:
Disclaimer: Zendesk provides the script for illustrative purposes only. Zendesk does not support or guarantee the code in the script. Zendesk also can't provide support for third-party technologies such as Python.
About the Access Logs API
The Access Logs API lets admins export up to the last 90 days of account access activity by team members. Team members include both admins and agents but not end users.
The API lets you filter the logs by a time period, a specific user, or a specific resource, such as tickets. You can also use scripting to further filter the data returned.
Each log represents an access event and includes the following information:
- an identifier of the resource that was accessed (see Identifying the accessed resources)
- the id of the user who accessed the resource
- the timestamp of when the user accessed the resource.
The log also includes other related information. See Access Logs.
Example access log:
{"id": "01H7TC9307Z5S07QPRW8REK5RD","ip_address": "52.40.158.85","method": "GET","origin_service": "Zendesk","status": 200,"timestamp": "2023-08-14T15:57:48Z","url": "/api/v2/users/417198039213/{...}","user_id": 364425201147},
In the example, a team member with the id of 364425201147 accessed the profile of a user with the id of 417198039213, as identified by the url property. The team member accessed the resource on 2023-08-14 at 15:57:48 UTC.
Identifying the accessed resources
The access logs indirectly identifies the resource that a user accessed by providing one of the following identifiers:
- the URL path of the REST API endpoint used to access the resource
- the GraphQL query used to access the resource
Many resources in the Zendesk frontend are accessed by REST APIs. REST APIs use uniform resource identifiers (URIs) to address resources. If a REST API was used to access a Zendesk resource, the url property in the access log will specify a URI that identifies the resource. Example: "url": "/api/v2/users/417198039213". In this example, the user accessed the profile page of the user with the id of 417198039213. To learn more about API URIs, see REST API URI Naming Conventions and Best Practices on restfulapi.net.
Other parts of the Zendesk frontend are accessed using GraphQL, a query language for APIs.
If a GraphQL query was used to access a resource, the access log will specify "/graphql" as the value of the url property. In addition, the log will include a graphql object with the following properties: operation_name, operation_type, query, and variables. All other log information is the same.
The query property may specify something like "query ticket" or "query user" and the variables property will specify the id of the ticket or user to look up.
REST API identifier example
{"id": "01H7TC9307Z5S07QPRW8REK5RD","ip_address": "52.40.158.85","method": "GET","origin_service": "Zendesk","status": 200,"timestamp": "2023-09-16T19:00:00Z","url": "/api/v2/search/incremental?{...}&query=agent guidelines","user_id": 364425201147},
In the example, the url indicates that the user searched for "agent guidelines".
GraphQL identifier example
{"graphql": {"operation_name": "ticket","operation_type": "QUERY","query": "\"query ticket($id: ID!, $includeSkills: Boolean = false, $includeCustomFields: Boolean = false, $includeUserCustomFields: Boolean = false, $includeConversationAuthenticated: Boolean = false) { ticket(id: $id) { id assignee { user { id name __typename }...","variables": "{\"id\":\"199\",\"includeConversationAuthenticated\":false,\"includeCustomFields\":false,\"includeSkills\":true,\"includeUserCustomFields\":false}"},"id": "01H7TC933PWS5B33SS5QHYZVKB","ip_address": "52.40.158.85","method": "POST","origin_service": "Zendesk","status": 200,"timestamp": "2023-08-14T15:57:49Z","url": "/graphql","user_id": 364425201147},
In the example, the query property specifies "query ticket ($id: ID!...), ...". The $id is a variable and its value is specified in the variables property as "{\"id\":\"199\", ...". This means the user accessed a ticket with the id of 199.
Rate limits
Requests are rate limited to 50 requests per minute, including pagination requests. Accordingly, you should use the maximum page size of 2500 to get the most records before reaching the limit.
The Access Logs API doesn't follow the same rate limiting conventions as other Zendesk APIs. Responses don't include x-rate-limits and x-rate-limit-remaining headers. The API does return a 429 status code when the limit is reached but doesn't include a retry-after header. You should use a "retry after" value of 60 seconds in your code.
Limitations
The Access Logs API has the following limitations:
-
The API only indirectly identifies a resource that an agent accessed. The identifier is either the URL of the API endpoint used to access the resource or the GraphQL query used to access the resource. A basic knowledge of REST APIs and GraphQL queries is required to interpret the data.
-
If you move your account to another pod (point of delivery), you’ll lose access to the access information in the old pod. This data is not copied over.
-
There are still some parts of the product where access information is not gathered. Examples include Explore and Sell.
What you'll need
This article provides a script that uses the Access Logs API to export the access logs to a CSV (comma-separated values) file. To run the script in this article, you'll need the following:
-
A Zendesk account
You'll need admin permissions to a Zendesk account with the Zendesk Advanced Data Privacy and Protection add-on.
-
Python
The script in this article uses the Python programming language. To install the latest version of Python, see http://www.python.org/download/.
-
Requests library for Python
The Python script uses the Requests library for Python. The Requests library simplifies making API requests in Python. To install it, make sure you install Python first and then run the following command in your terminal:
pip3 install requests -
Arrow library for Python
The Python script uses the Arrow library for Python. The Arrow library provides a friendlier, more streamlined way of working with dates and times. To install it, make sure you install Python first and then run the following command in your terminal:
pip3 install arrow
Note: Some lines of code in the examples may wrap to the next line because of the article's page width. When copying the script, ignore the line wrapping. Line breaks matter in Python.
Creating the export script
-
Create a folder called access-log-export on your system.
-
In a plain text editor, create a file named export_logs.py and save it in the folder.
-
Paste the following code in the file:
import jsonfrom csv import writerfrom pathlib import Pathfrom time import sleepimport reimport requestsimport arrowimport os"""Specify your Zendesk subdomain and credentials. In production, use environment variables instead."""ZENDESK_SUBDOMAIN = 'yoursubdomain'ZENDESK_USER_EMAIL = '[email protected]'ZENDESK_API_TOKEN = os.getenv('ZENDESK_API_TOKEN')def export_agent_access_logs() -> list:"""Asks the user for a resource (tickets or users) that agents have accessed in the last number of days. Exports the results to a CSV file.:return: A list of tickets or users that agents accessed, the agents that accessed them, and when they accessed them"""# -- Ask for the resource and the number of days -------------- #while True:resource = input('Specify a resource (tickets or users): ')if resource in ['users', 'tickets']:breakelse:print('Not a valid option. Try again.')while True:days = input('Specify number of days back to look (1 to 90): ')if days.isdigit() and 1 <= int(days) <= 90:days = int(days)breakprint('Not a valid option. Try again.')# -- Get agents ----------------------------------------------- #print('Getting the agents...')agents = []api_list_name = 'users'url = f'https://{ZENDESK_SUBDOMAIN}.zendesk.com/api/v2/users'params = {'page[size]': 100}users = get_api_list(api_list_name, url, params)for user in users:if user['role'] == 'agent':agents.append(user)# -- Get agent access logs ------------------------------------ #print('Getting their access logs. One moment, please...')agent_access_logs = []api_list_name = 'access_logs'url = f'https://{ZENDESK_SUBDOMAIN}.zendesk.com/api/v2/access_logs'end_time = arrow.utcnow()filter_end = end_time.format('YYYY-MM-DD[T]HH:mm:ss[Z]')start_time = end_time.shift(days=-days)filter_start = start_time.format('YYYY-MM-DD[T]HH:mm:ss[Z]')params = {'filter[start]': filter_start,'filter[end]': filter_end,'page[size]': 1000}for agent in agents:params['filter[user_id]'] = agent['id']access_logs = get_api_list(api_list_name, url, params)for log in access_logs:log['agent_name'] = agent['name']agent_access_logs.extend(access_logs)# -- Filter the logs by the specified resource ---------------- #agent_resource_access_logs = []identifiers = {'tickets': {'api': '/api/v2/tickets/', 'graphql': 'query ticket'},'users': {'api': '/api/v2/users/', 'graphql': 'query user'}}resource_identifiers = identifiers[resource]for log in agent_access_logs:# look for the resource in the api requestif 'api' in resource_identifiers and resource_identifiers['api'] in log['url']:match = re.search(r'\d{2,}', log['url'])if match:log['resource_id'] = match.group()agent_resource_access_logs.append(log)# look for the resource in the graphql queryelif 'graphql' in log:if 'graphql' in resource_identifiers and resource_identifiers['graphql'] in log['graphql']['query']:variables = json.loads(log['graphql']['variables'])if 'id' in variables:log['resource_id'] = str(variables['id'])agent_resource_access_logs.append(log)if not agent_resource_access_logs:print(f'Agents did not access any {resource} in the last {days} days.')return []# -- Create the CSV file -------------------------------------- #resource_name = resource[:-1].capitalize()rows = [(f'Agent ID','Agent name',f'{resource_name} accessed','Time accessed')]for log in agent_resource_access_logs:row = (log['user_id'],log['agent_name'],log['resource_id'],log['timestamp'])rows.append(row)file_path = Path(f'agent_{resource}_access_logs_{filter_start}-to-{filter_end}.csv')with file_path.open(mode='w', newline='') as csv_file:report_writer = writer(csv_file, dialect='excel')for row in rows:report_writer.writerow(row)print(f'A CSV file called {file_path} was created in the current folder.\n'f'Import it into your favorite spreadsheet application.\n')return agent_resource_access_logs# -- API request function ----------------------------------------- #def get_api_list(api_list_name, url, params) -> list:"""Makes an API request to a Zendesk list endpoint and returns a list of results.:param str api_list_name: The name of the list returned by the API. Examples: 'access_logs' or 'users'. See the reference docs for the name:param str url: The endpoint url.:param dict params: Query parameters for the endpoint.:return: List of resource records."""api_list = []# Zendesk API token usage in the format 'email/token:api_token'auth = f'{ZENDESK_USER_EMAIL}/token', ZENDESK_API_TOKENwhile url:response = requests.get(url, params=params, auth=auth)if response.status_code == 429:if 'retry-after' in response.headers:wait_time = int(response.headers['retry-after'])else:wait_time = 60print(f'Rate limited! Please wait. Will restart in {wait_time} seconds.')sleep(wait_time)response = requests.get(url, params=params, auth=auth)if response.status_code != 200:print(f'Error -> API responded with status {response.status_code}: {response.text}. Exiting.')exit()data = response.json()api_list.extend(data[api_list_name])if data['meta']['has_more']:params['page[after]'] = data['meta']['after_cursor']else:url = ''return api_listif __name__ == '__main__':export_agent_access_logs() -
Save the file.
Exporting access logs with the script
Before running the script for the first time, update the values of the variables at the top of the file:
ZENDESK_SUBDOMAIN = 'yoursubdomain'ZENDESK_USERNAME = '[email protected]'ZENDESK_TOKEN = os.getenv('ZENDESK_API_TOKEN')
Follow best practices for handling API tokens and never hard-code your API token within your source code. Here, we define the environment variable ZENDESK_API_TOKEN to contain the token.
To run the script
-
In your terminal, navigate to your access-log-export folder.
-
Enter the following command and press Enter.
python3 export_logs.py -
Follow the prompts.
The script creates a CSV file in your access-log-export folder. Import the CSV file into a spreadsheet application.
Modifying the script
If you want, you can modify the script. This section describes the different parts of the script so you have a better understanding of how it works before making changes to it.
Updating the authentication credentials
The script uses API tokens, which only requires the user name and API token of a Zendesk admin:
ZENDESK_USERNAME = '[email protected]'ZENDESK_TOKEN = os.getenv('ZENDESK_API_TOKEN')
You should use environment variables in production. In Python, you can retrieve the environment variables as follows:
import osZENDESK_USERNAME = os.environ['ZEN_USER']ZENDESK_TOKEN = os.getenv('ZENDESK_API_TOKEN')
You can also use other authentication methods such as an OAuth token. For more information, see Security and authentication.
Adding admins
In addition to agents, you could include the access logs of admins. When getting the agents from the Users API, include users with the role of admin too:
for user in users:if user['role'] == 'agent' or user['role'] == 'admin':agents.append(user)
Filtering the logs by other identifiers
You can add other identifiers in addition to the ones for tickets and users. In the "Filter the logs by the specified resource" section of the script, add the new resource's identifiers in the identifiers dictionary. The following example adds ticket forms:
identifiers = {'tickets': {'api': '/api/v2/tickets/', 'graphql': 'query ticket'},'users': {'api': '/api/v2/users/', 'graphql': 'query user'},'ticket_forms': {'api': '/api/v2/ticket_forms/', 'graphql': 'query ticket_forms'}}
Then modify the API and GraphQL filters as necessary to handle the new identifiers.
Finally, add a new option that the user can enter when they start the script:
resource = input('Specify a resource (tickets, users, or ticket_forms): ')if resource in ['users', 'tickets', 'ticket_forms']:break
Getting additional details about the accessed tickets or users
You can make other requests to the Zendesk API to get additonal details about the tickets or users that agents accessed and then add the information to your CSV file. See Show Ticket or Show User in the API reference.
For example, after populating the agent_resource_access_logs variable in the script, you could add the following for loop to iterate over all the accessed tickets or users and make a request for the record for each:
for log in agent_resource_access_logs:url = f'https://{ZENDESK_SUBDOMAIN}.zendesk.com/api/v2/{resource}/{log["resource_id"]}'data = get_api_resource(url)log['resource_record'] = data# ... add additional details to the CSV file
The loop uses a different function to make the API requests. The get_api_list() function in the main script wouldn't work in this case because these endpoints only return a single record at a time and don't use pagination. Here's a possible function you could use to make requests for single records:
def get_api_resource(url):"""Returns a single resource record.:param url: A full endpoint url, such as 'https://example.zendesk.com/api/v2/tickets/12345:return: The specified record of the resource"""auth = f'{ZENDESK_USER_EMAIL}/token', ZENDESK_API_TOKENresponse = requests.get(url, auth=auth)if response.status_code == 429:print('Rate limited! Please wait.')sleep(int(response.headers['retry-after']))response = requests.get(url, auth=auth)if response.status_code != 200:print(f'Error -> API responded with status {response.status_code}: {response.text}. Exiting.')exit()# return only the resource data, not the name of the resourcefor resource_name, resource_data in response.json().items():return resource_data